Overview

Instance Detection (InsDet) is a practically important task in robotics applications, e.g., elderly-assistant robots need to fetch specific items from a cluttered kitchen, micro-fulfillment robots for the retail need to pick items from mixed boxes or shelves. Different from Object Detection (ObjDet) detecting all objects belonging to some predefined classes, InsDet aims to detect specific object instances defined by some examples capturing the instance from multiple views.
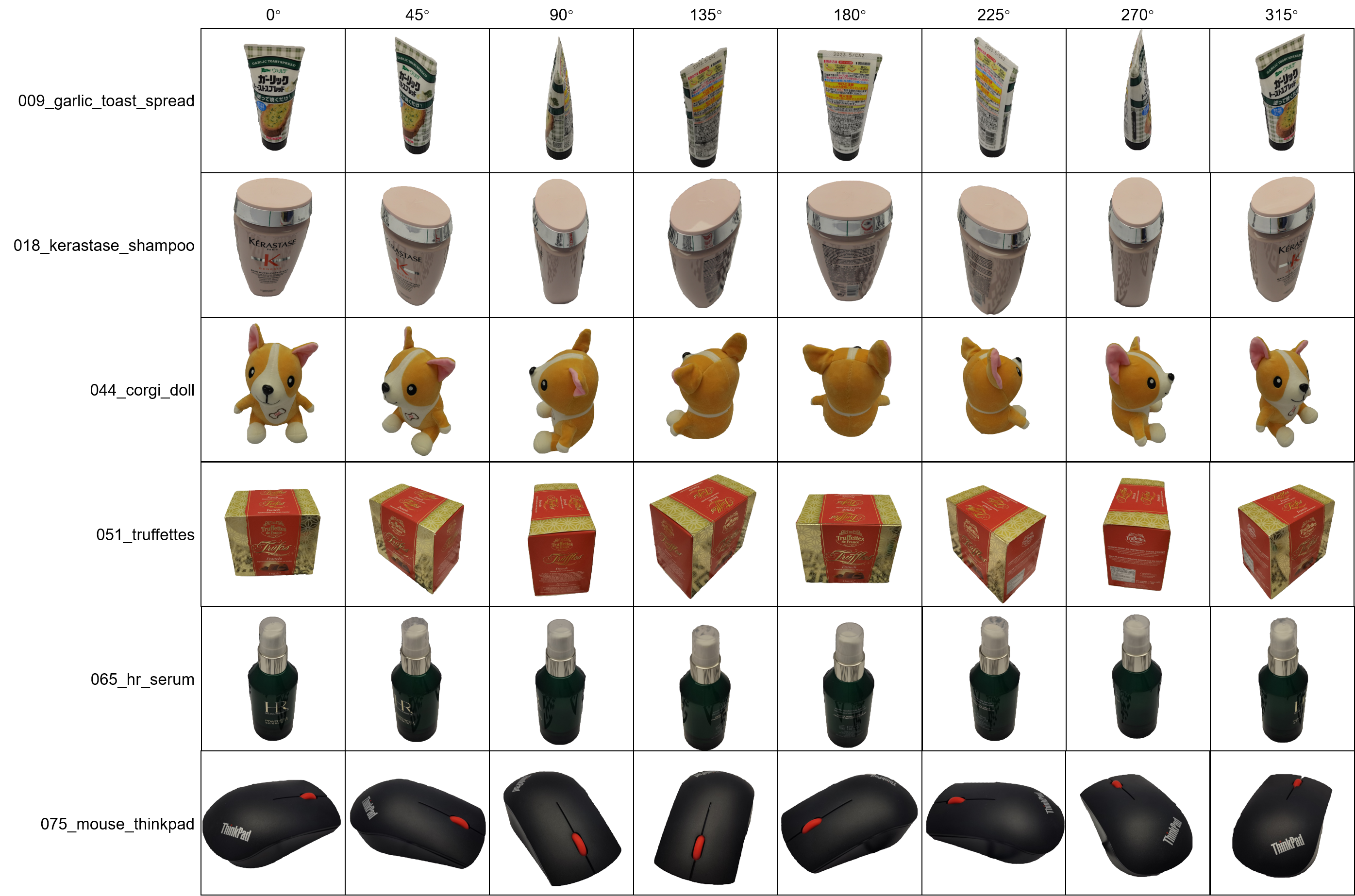
This year, we plan to run a competition on our InsDet dataset, which is the instance detection benchmark dataset which is larger in scale and more challenging than existing InsDet datasets. The major strengths of our InsDet dataset over prior InsDet datasets include (1) both high-resolution profile images of object instances and high-resolution testing images from more realistic indoor scenes, simulating real-world indoor robots locating and recognizing object instances from a cluttered indoor scene in a distance (2) a realistic unified InsDet protocol to foster the InsDet research.
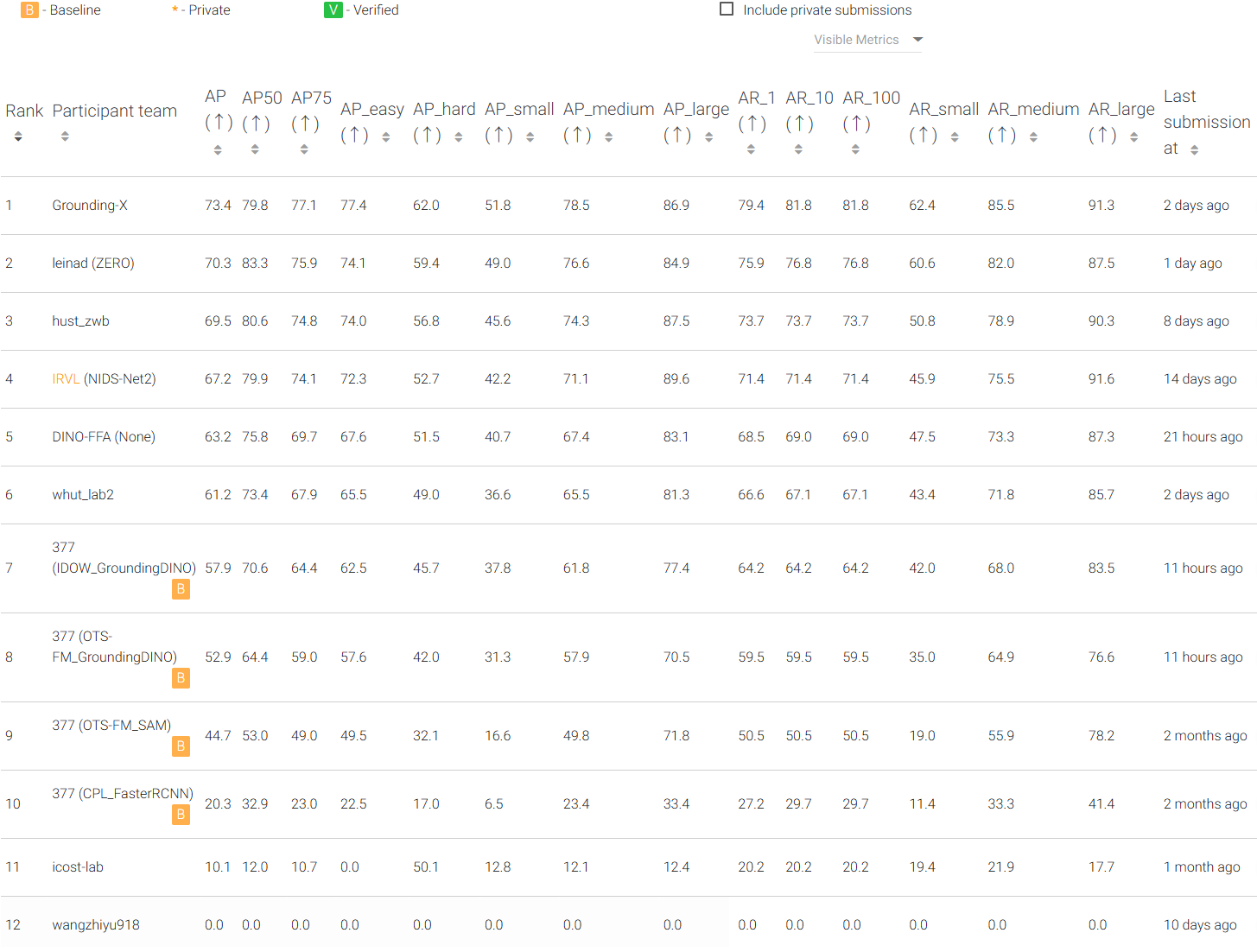
Participants in this challenge will be tasked with predicting the bounding boxes for each given instance from testing images. This exciting opportunity allows researchers, students, and data scientists to apply their expertise in computer vision and machine learning to address instance detection problem. We refer participants to the user guide for details.